Description
Typically, Object Detectors and Classifiers are composed of Convolutional Neural Networks (CNNs) that can exhibit human-like feature extraction, but can also have unrelated difficulty in comprehensively comprehending the contents of an image. Understanding how such a neural network can behave when non-ideal images are processed can be integral for real-time applications. Additionally, implementing methods of correcting damaged or “degraded” images can also prove very useful.
This project intends to explore the effects of certain degraded images on the performance of popular or state-of-the-art Object Detectors and Classifiers implemented for real-time applications. For clarification, an augmentation function that worsens the interoperability of an image is a “degradation;” a method that does the opposite is a “correction.”
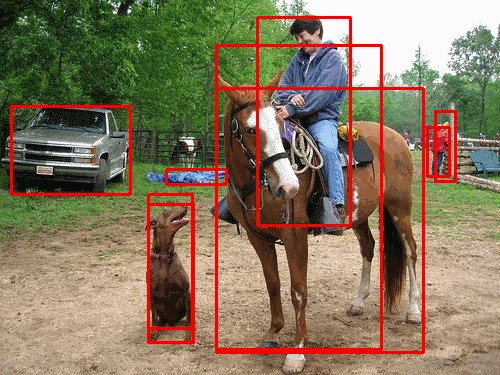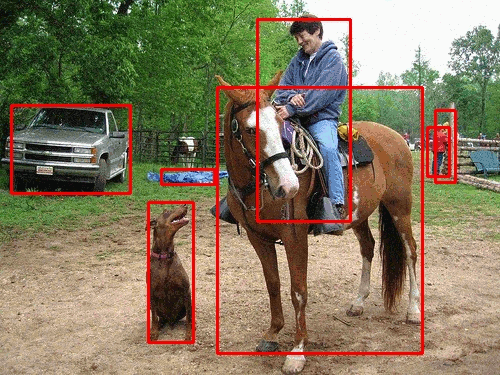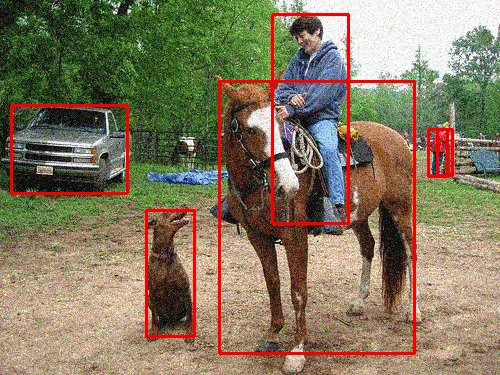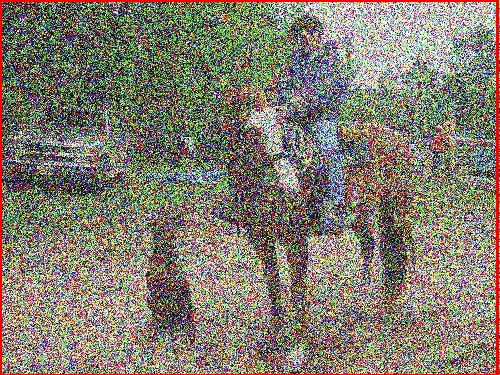
Based on their occurrences in real-life scenarios and applications, different degradations, such as Gaussian Noise, Gaussian Blur, and Salt & Pepper, were chosen to be applied onto very popular, real-time networks such as YOLOv3 (You-Only-Look-Once) and ResNet50. A certain parameter for a given degradation method was adjusted to increase the pronounced effect on the images. The value ranges of each degradation’s parameter was qualitatively assessed by different perceptual image metrics, such as SSIM. Analyzing the performance of these CNNs against each degradation tells a unique story.
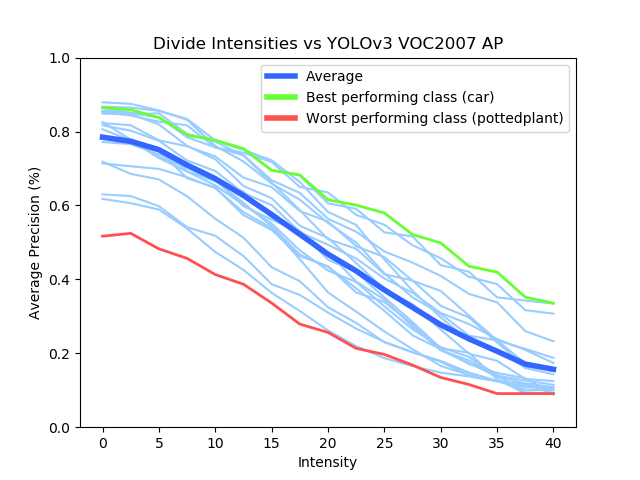
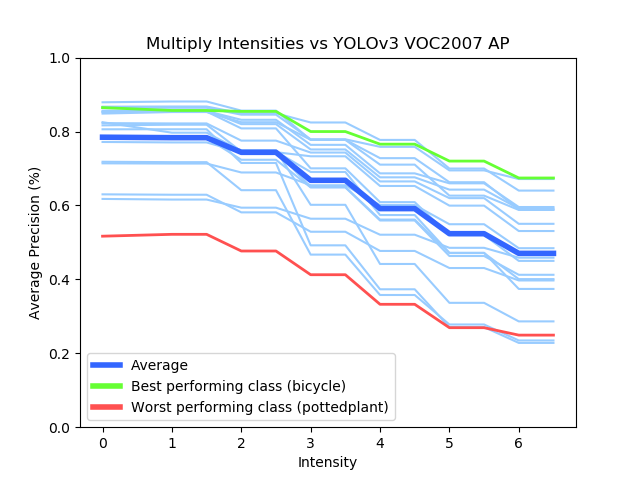
For example, lets take a look at the graphs above. The two degradations have a widely different pattern of Mean Average Precision (main metric of Object Detectors) loss, even though one simply darkens an image and another lightens an image, respectively. Moreover, it can also be noted that different object classes can behave better or worse compared to other classes based on many different factors, such as appearance, variety, and training amount.
Furthermore, corrections such as Median Filter and FFT were used to restore images enough for the CNNs to regain some lost performance. These corrections had their own set of parameters that could be changed for varying effects. Combined with the variability of the degradation methods, the overall conclusion was that, for a given degraded image, a certain correction level was needed to regain the most mAP performance.
Further Work
Current students are expanding upon the aforementioned findings to apply more augmentations to different CNNs and other Vision Networks. Additionally, work in correcting a degraded image frame and training with robustness is being currently explored.